8. Text Processing algorithms for keywords¶
8.1. Automatic Keywords¶
Automatic keywords are computed by TIM for each type of document. Autokeywords or Automatic keywords are computed by text mining techniques using the text of the documents available in tilte, description and author keywords (if any). For a concept to be selected as automatic keyword, it has to have been used as an author keyword in a document. A variable number of words (10-15) are attributed by TIM to each document. This field is attributed to all types of documents in the system, including those that do not have author keywords.
8.2. Relevant Keywords¶
This page displays the most relevant keywords in the dataset and their relevance score. These keywords are generated by language processing algorithms to represent the dataset as a whole.
The keywords are presented in an ordered list of terms with an associated score, or rank. The value measures the “relevance” of the term in the dataset.
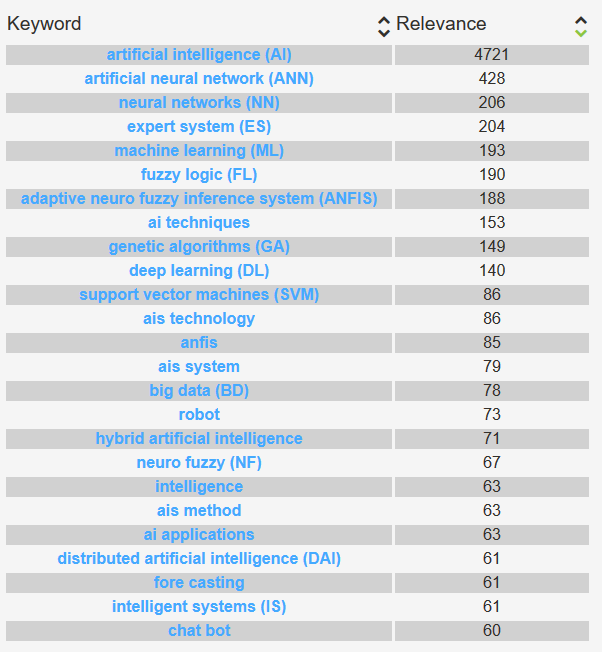
The relevant keywords page is a representation of the concepts identified in the dataset. TIM extracts the “concepts” for each of the documents in the dataset. The concepts are a list of single or multi-term words.
The bag of concepts is a list of terms with a rank associated to each term. For each of these concepts, the Inverse Document Frecuency (IDF) is calculated, where
The idea behind the IDF calculation is that more weight is given to the terms that are more rare. To calculate the rank:
where frequency is the number of times the concept appears in dataset and mod_field is a modifier that gives more or less weight to the terms depending on where they are found (title, abstract or keyword). In this specific case, the modifier is calculated as follows: Title: 1 Abstract: 0.5 Keyword: 2 This is made so that the “important” words are attributed a higher rank.
The bag of concepts can be calculated at the level of individual documents or for a group of documents. In the case of relevant keywords, it is the bag of concepts for the dataset (your search).