2. Search¶
Contents
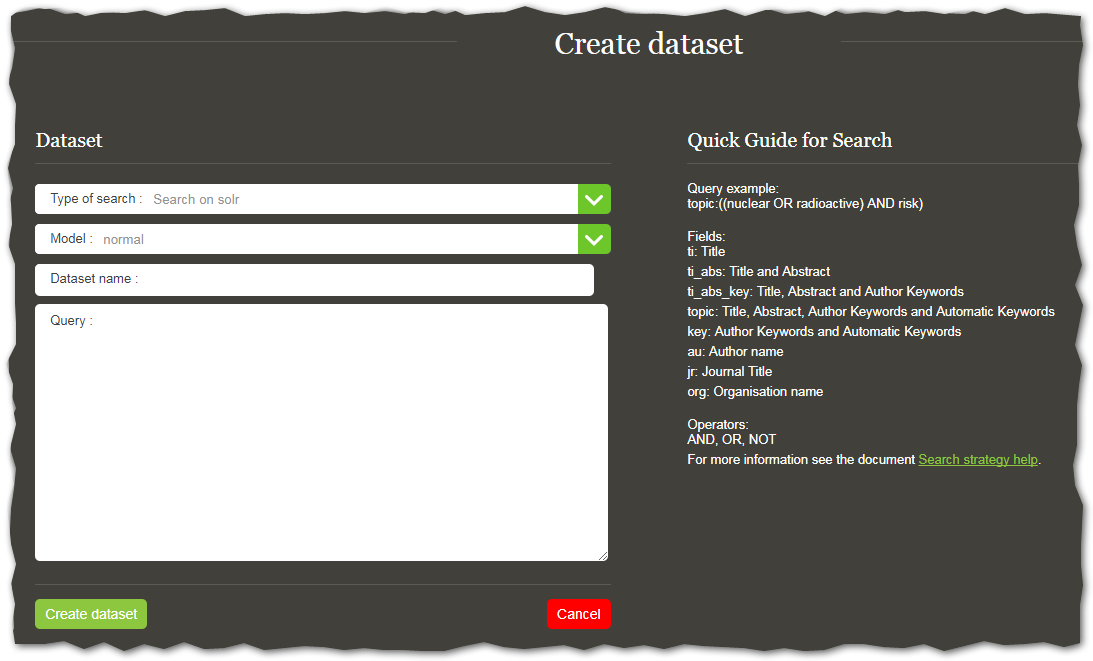
2.1. Create a dataset¶
A dataset is a collection of documents that can be analysed and visualised together. Datasets are normally defined using a structured search string that retrieves the matched documents from the TIM database.
To create a new dataset, click on CREATE Dataset in the navigation panel (3).

The Create Dataset page is loaded.
Type a name in Dataset name and enter the search string in the field Query (see the next section on how to build a search string).
The option Model should be left with the default value (normal).
The option Type of Search refers to the group of documents you want to search in.
The current options available are:
Search on Solr: searches on publications from Semantic Scholar, patents from patstat and EU projects from CORDIS.
Search on COVID-19 Open Research Dataset (CORD-19): searches on publications on COVID-19 and coronavirus-related documents.
The Model option offers some dataset processing options to the power user, among which is the ability to lift the 10,000 document limitation.
As this is generally not encouraged for reasons of both performance and readability of the graphs, these options are hidden.
If you have a specific need for that kind of functionality, you can contact us at JRC-TIM-SUPPORT@ec.europa.eu.
2.2. How to build a search query¶
The aim of this section is to provide some guidelines for TIM users when designing a search query. The search functionality is based on queries using a specific syntax. The query will retrieve documents from the TIM database of scientific publications, patents and EU granted projects, which will constitute the dataset. The dataset can then be visualised through the various pages available.
A search query is composed of a combination of fields, terms and operators.
Note
Terms refer to what you want to search for
Fields refer to where you want to search for it
Operators help you combine more than one field or more than one term, to construct more elaborate search queries.
2.2.1. Fields¶
Data indexed in TIM is structured and organised in fields, such as title, abstract, location, year. For this reason, when forming a query, the fields to be searched need to be specified. Depending on the group of documents selected earlier, the fields available differ.
The most important fields that are searchable for CORD-19 are the following:
operator name |
Searches in |
|---|---|
title |
field |
description |
field |
text |
full text of the document (when available). |
emm_year |
publication year of the article |
emm_journal |
journal of the publication |
emm_autoKeywords |
Automatic keywords generated by TIM |
emm_doi |
DOI of the article |
guid |
unique TIM ID of the article |
emm_cord_uid |
unique CORD-19 ID |
emm_affiliation__city |
City of the organisation publishing |
emm_affiliation__country |
Country of the organisation publishing |
emm_affiliation__countryCode |
Country code of the organisation publishing |
emm_affiliation__name |
Name of the organisation publishing |
emm_author__name |
authors’ names |
The most important fields that are searchable for Semantic Scholar are the following:
operator name |
Searches in |
Refers to the |
|---|---|---|
ti |
field |
title of the publication, patent or EU granted project. |
ti_abs |
fields |
abstract of the publication, patent or EU granted project. |
topic |
Used to search in the fields |
Automatic keywords are terms generated automatically by natural language processing algorithms. Automatic keywords are generated for all types of documents. |
au |
Used to search in the field |
Author refers to the name of the author in a publication or the name of the inventor of a patent. |
org |
Used to search for the organisation publishing an article, applying for a patent (applicant) or participant of a grant. |
The information about organisation is retrieved from: affiliation of authors, applicants of patents, participants in EU project. |
Users can specify a field, by typing the field name followed by a colon : and then the term or phrase of interest within that field.
For example, to find a document that contains the term electrolyte in the title, the query should be constructed as follows:
ti:
electrolyteThe field is only valid for the term that it directly precedes, so the query
ti:
functional dynamicswill only find
functionalin the title field and will ignore the term following it. If you want to search for the phrasefunctional dynamics, the query should be within double quotes.ti:
"functional dynamics"This is called an exact search.
Exact searches can also be made in a few additional fields:
class |
Usage |
|---|---|
emm_year |
Use the year number or for periods use [year TO year] |
emm_affiliation__ecountry emm_affiliation__ecity emm_affiliation_nuts |
The exact English version of names of countries and cities can be searched. For NUTS (Nomenclature of Territorial Units for Statistics), you can refer to the full list at Eurostat[1]. |
emm_classificationCPC |
Each patent belongs to one or more CPC classification. For the nomenclature of patent classes see Espacenet.[3] |
Exact search means that you have to put the exact text (case sensitive) if you want to find a match.
So, if for example you search for emm_affiliation__ecountry:United, this
will not match United Kingdom, or any other country starting with United and followed by more characters.
Also, emm_year:99 will not work.
You can, however, write emm_year:*99, or emm_year:19*, as single term modifiers will work as usual.
To filter by document type in the search string, use the following:
Documents Class | To be used in the search string |
|
|---|---|
Patent |
class:patent |
EU project |
class:euproject |
Note
Not all the available fields are described in this document. Please contact us for more complex searches.
2.2.2. Terms¶
2.2.2.1. Stemming¶
Before talking about terms in general, it is important to mention stemming. Stemming is a process that reduces words to their word stem, or root. For example:
technologiesbecomestechnolog-
This means that if you search for the word technologies or technology, TIM will understand you are looking for documents containing a word whose stem is technolog and hence will match:
technology,technological,technologically.
TIM applies stemming to the search terms inputted by the users, in order to widen the set of matched documents. It also simplifies the search query, as the user doesn’t have to input all possible variants of some words.
That said, there are some cases that should be handled with care. If, for example, the user makes a search:
topic:"operating system"
then the stem of the word operating is operat, which means that this will also match operative system and operational systems, which might not be what the user had in mind.
In this case, the user should try to narrow down the search by contextualising it to the area of interest, so as to avoid matching the other variants.
This also has implications on how Term modifiers are used.
TIM uses the de facto standard algorithm for stemming (Porter’s), and there exist a few stemming testers freely on the internet, on which the user, if not certain, can test how a word gets stemmed. For an example webpage, see this.
It is advisable to consult with stemmers because sometimes results can be surprising.
For example, in the case of printers and printing, it turns out that these two words don’t have the same stem!
Printers’s stem isprinter-Printing’s stem isprint-
See Stemming and wildcard searches on how this can impact a search query.
2.2.2.2. Types of terms¶
There are two types of terms: single terms and phrases
A single term is a single word, such as
emissionornanoparticle.Again, it’s important to understand that what is searched for is words whose stem is
emiss-andnanoparticl-, respectively.- A phrase is two or more words surrounded by quotation marks, such as
"rapid prototyping method"(="rapid prototyp- method")
When a phrase is used in a search query, documents matching the exact phrase will be retrieved.
A search for the phrase "rapid prototyping" will not retrieve the documents containing the phrase rapid and cheap prototyping, but will retrieve the ones containing solid-based rapid prototyping.
Note
Some of the fields in TIM store text in a different way. For example, when the text in a field is actually representing identifiers or codes, where spaces might be significant, the text is stored as a continuous string. More information is covered in chapter Fields in TIM.
2.2.2.3. Term modifiers¶
Term modifiers allow the User to introduce flexibility or precision in the terms used for a search. They include wildcard characters, characters for making a search “fuzzy” or more general, and so on. The sections below describe these modifiers in detail.
2.2.2.3.1. Wildcard Searches¶
TIM search engine supports single and multiple character wildcard searches within single terms. Wildcard characters can be applied to single terms, but not to search phrases.
? |
Single character (matches a single character). |
* |
Multiple characters (matches zero or more sequential characters) |
For example, the search string:
ti:te?twill match both
textandtestin the title of the document.The search string:
ti:electroly*will match electrolyt-e, electrolyt-ic, electrolys-is, electrolys-er and electrolyz-er and others in the title of the document. In reality, it will be matching stems
electrolyt-andelectrolys-.You can also use wildcard characters in the middle of a term. For example:
ti:leuk*miawould match leukaemia and leukemia in the title of the document.
Last, you can use wildchard characters in the beginning of a term. For example:
ti:*leukaemiawould match, besides leukaemia, erythroleukaemia.
2.2.2.3.2. Proximity Searches¶
A proximity search looks for terms that are within a specific distance from one another.
To perform a proximity search, add the tilde character ~ and a numeric value to the end of a search phrase, and enclose the whole block in parentheses.
The number signifies the distance that two words can be apart, or the number of word movements that need to be performed to get from the matched string to the phrase we have provided.
The latter concept is a bit more complicated, but works better when using proximity search on phrases with more than two words.
Example
To search for nuclear and waste within 5 words of each other in the topic of a document, use the search:
topic:("nuclear waste"~5)
In this example , the search would match a document containing the following text:
…nuclear and biological waste….
and also a document containing the text “….in nuclear plants, radioactive waste is treated……”.
Example
If the user types:
topic:("low-dose radiation"~4) (note the use of parenthesis in both cases)
then this is one of the results: “…induced by low dose irradiations; its impact on radiation protection”.
The distance referred to here is the number of term movements needed to go from the specified phrase, low-dose radiation to the matched phrase.
It is convenient to visualise this as consecutive word transpositions/insertions of the unrelated terms (irradiations, its, impact, on) outwards, until they are out of the specified phrase (or in, depending on your starting point).
The same result would have been retrieved by using:
topic:("low irradiations impact"~4)
because the same number of words needs to be inserted. If, however, you were to give the query with e.g. two terms reversed:
topic:("irradiations low impact"~4)
then this would no longer work with
~4, you would have to use~5, because an extra transposition is required.
2.2.2.3.3. Range Searches¶
A range search specifies a range of values for a field (a range with an upper bound and a lower bound). The query matches documents whose values for the specified field or fields fall within the range. Square brackets [ ] denote an inclusive range query that matches values including the upper and lower bound.
For example, one could search in the field relating to the year of publication using:
emm_year: [2002 TO 2004]
2.2.3. Operators¶
Boolean operators allow you to apply Boolean logic to queries, requiring the presence or absence of specific terms or conditions in fields in order to match documents.
The table below summarizes the Boolean operators supported by TIM.
AND |
All search terms must occur to be retrieved |
The search string: (nanomaterial AND toxicity) will retrieve documents that contain both terms. |
OR |
Any one of the search terms must occur to be retrieved. Use when searching variants and synonyms. |
The search string: (nanomaterial OR nanotube OR nanoparticle) will retrieve documents that contain at least one of the terms. |
NOT |
Excludes records that contain a given search term |
The search string: (nanomaterial NOT inflammation) will retrieve documents that contain nanomaterial excluding any which also contain inflammation. |
In order to be recognised as such by the software, the Boolean operators should always be used in capital letters.
2.2.3.1. Grouping¶
a) Parentheses are used to group terms into sub-queries, or to group sub-queries into larger queries. This allows you to control the Boolean logic for a query.
If, for example, you have variants for the concept of nanomaterial, you can combine them with multiple OR operators, and enclose everything in parentheses:
topic:(nanomaterial OR nanotube OR nanoparticle)Do not ommit the parentheses!
topic:nanomaterial OR nanotube OR nanoparticlewould only yield results for
topic:nanomaterialand discard the rest of the query.
You can further craft your search query, for example requiring that the term toxicity exists, along with either of the nanomaterial terms you are using.
topic:((nanomaterial OR nanotube OR nanoparticle) AND toxicity)
Parentheses have to be used always when combining terms in one search field, but are not strictly necessary when combining sub-queries of different fields.
topic:(nanotube AND toxicity) AND location:Switzerland
Here you have to enclose nanotube AND toxicity in parentheses, but you don’t have to also enclose the whole line in parentheses. However, if you add more Boolean operators, confusion will be unavoidable if you don’t enclose your sub-queries in parentheses.
topic:A AND location:B OR class:C
is different to
topic:A AND (location:B OR class:C)
so you should make sure to be as explicit as possible, by always using parentheses.
If two terms are written consecutively inside parenthesis, without using quotes, then the AND operator is implied.
For example, if you write:
topic:(nanomaterial toxicity)
it will be treated as if you had written
topic:(nanomaterial AND toxicity)
It should also be noted that, for fields combining more than one field, such as topic and ti_abs_key, TIM will try to match all the terms given, in one field after the other.
So, for example, if you search
topic:(nuclear AND risk)
TIM will first search in the title for both nuclear and risk. If it fails, it will then proceed to search in the description, if it fails it will move on to the author keywords, and so on and so forth. This is illustrated in the article below, where the above search fails (i.e. the document below will not be retrieved), as the two words are never found together in the same field.

If you want to match for both the words anywhere in the topic, i.e. you don’t care if nuclear is in the title and risk is in the keywords, then you have to explicitly state it, by searching:
topic:nuclear AND topic:risk
2.2.4. Search Query Examples¶
topic:((nanoparticle OR nanogranule) AND medicine)
key:``synthetic biology``
ti_abs_key:soil AND org: ``joint research centre``
ti:(3D AND print) NOT emm_journalCategoryScopus: ``Biophysics OR Biochemistry``
key:(GNSS OR ``global navigation satellite system)``
topic:( ``low-dose radiation``~5 AND protect*) AND emm_year:[2002 TO 2004]
2.3. Validate Dataset¶
The goal of the search functionality in TIM Technology is to define a dataset to be visualised and interpreted.
A dataset is a set of patents, publications and projects that are specific to a scientific domain, field or technology that has been defined by the user. The quality of the dataset is of utmost importance, as it will constitute the basis for all the visualisation(s). When the user submits a search query, a screen for the validation of the dataset is displayed.

The first twenty results of the search performed by TIM will be displayed to assess the relevance of the search strategy used.
Once created, the dataset can be saved by clicking on the Submit button.
If the preview of the results seems to indicate that the results are not relevant, the search string needs to be refined or modified.
To do so, you can use the back button.
TIM Technology limits the size of datasets to 10.000 documents. If a search results hits that maximum, it is recommended to refine the search in order to have a smaller, more meaningful dataset that is easier to visualise and interpret.
2.3.1. Assess the quality of the results of the Search - Recall and Precision¶
Bibliometricians have been using the concepts of precision and recall to measure the quality of an information retrieval. Precision is the ratio of the number of relevant records retrieved to the total number of records retrieved (irrelevant and relevant). Recall helps to measure the proportion of relevant documents out of all the documents retrieved. It is calculated as the ratio of the number of relevant records retrieved to the total number of relevant records in the database. It is usually expressed as a percentage. Recall and precision are inversely related. It is important to keep these concepts in mind when designing a search and to balance them according to the goal of the search strategy.
2.4. Advanced¶
2.4.1. Alternative query syntax¶
There is an alternate query syntax that can be used in cases where the query becomes too long for TIM to parse. An often-seen case is when there is a list of a thousand documents, refered to by their IDs, connected by OR clauses. The format is:
_query_:"{!terms f=<FIELD>}<TERMS>"
where <FIELD> is a search field, such as emm_doi and <TERMS> is a list of the terms that you want to join together by OR, in this case, the actual DOIs.
For example,
_query_:"{!terms f=emm_doi}10.1024/0939-5911/a000458,10.1007/s00038-016-0830-z,10.1093/pubmed/fdw040,10.1016/j.socscimed.2017.04.031"
This is equivalent to:
emm_doi:(10.1024/0939-5911/a000458,10 OR 1007/s00038-016-0830-z,10 OR 1093/pubmed/fdw040,10.1016/j.socscimed.2017.04.031)
Caution
this will only work for specific fields, such as ID, year, country. For a full list, see here.
2.5. Common Pitfalls¶
2.5.1. Not all quotes are created equal!¶
Why does this search term produce 34400 results ? For the same reason the following gives 34280!
topic:(“4d printing”~2 OR "4-dimensional printing"~2)
Do you notice something strange about this query? the quotes used for the first term are different than the quotes used for the second term!
“4d printing” and "4d printing" is not the same thing!!
The short story is that you definitely want to avoid using “ ”.
This set of quotes usually comes from copying and pasting from and to microsoft office applications.
Make sure to use just notepad or wordpad when copy-pasting, so that the text is preserved as is.
The long story:
The “ ” are not regarded as quotes, they are regarded as normal characters, so what the system sees is:
first term:
“4d[a word consisting of a weird character, followed by 4d]second term:
printing”~2[the word printing followed by a weird character, and a modifier which in THIS case means that you want a word that looks like printing”, more or less!]third term:
"4-dimensional printing"~2[the exact term “4-dimensional printing”, with the possibility that one or two words are put somewhere in between, or the order is changed]
So what you were giving the system was A B OR C, which is going to be interpreted as A AND B OR C, and who can remember whether that is (A AND B) OR C, or A AND (B OR C) …
2.5.2. Over-use of the asterisk *¶
Take, for example, the term "Self*fold*".
You can write "self-fold" instead, without any asterisks (but always in quotes)
The first asterisk can be omitted, because if you look for "self-fold", the system will also automatically look for "self fold".
The second asterisk can be omitted because stemming does that for you automatically: when you look for "fold", "folded" and "folding" will also be matched.
However, keep in mind that, for terms separated with a dash that can also be found as single words, you will have to provide the single word variant yourself.
For example, cross-sectional can also be found in documents as crosssectional, so you have to make a query like so:
title:(cross-section OR crosssection)
2.5.3. Using asterisks with values containing spaces¶
Some special field values may contain spaces that are significant, e.g. emm_classificationCPC’s values usually have one or more spaces.
Searching for emm_classificationCPC:"G09G 3/20912" works as expected (that’s three spaces in there!).
It becomes a bit more complicated when the User wants to search e.g. for all classification codes that start with G09 G 3/20 and end in any number.
Adding an asterisk, emm_classificationCPC:G09G 3/209* will not work, as the
parser thinks this is emm_classificationCPC:G09G AND <something else>.
This is because what is after the space is not taken into account and the parser expects an operator at that position.
In these cases normally the value searched would be put within quotes, but asterisks don’t work with quotes.
So searching for emm_classificationCPC:"G09G 3/209"* won’t work either (please note that if the original search was without asterisk, the quotes would have worked as expected).
For this specific case to work, each space must be escaped:
emm_classificationCPC:G09G\ \ \ 3/209*
Note that each space has to be escaped separately. If you are not sure about the number of spaces, you could also attempt:
emm_classificationCPC:G09G\ *3/209*
2.5.4. Stemming and wildcard searches¶
Beware of cases such as printers and printing, as mentioned in the section above (Stemming):
title:(3D AND print*)will return documents that include3DAND (printingorprintersorprinteretc) in the title.title:(3D AND print)(without the asterisk) will return documents that include3DANDprintingbut notprinters.